


Pixel 3aは買わなかったんですか?
買いませんよ?さすがに。
お兄ちゃん(Pixel3XL)持ってますし。
てっきり買うのかと思ってましたよ?
何だと思ってるんですか。
しかし、今年は地味でしたね。
もっとヤバいの欲しかったですね?
地味でしたか?本当に?
グーグルによる世界征服が発表されたというのに?
呑気なものですね。
ん?
なんて?
普通、Google I/O 2019 のメインイベントと言えば?と問われば、Pixel 3a を思い浮かべません?
っていうか、わたしはそうでした。
でも、どうやら一番ヤバいのは Federation Learning じゃないか説。
わりとトンデモ理論かと思ったけど、サラッと流すには、ちょっと面白かったので、図にしてみました。
Federation Learning (フェデレーションラーニング)
直訳すると連合学習ですが、つまり連合を組んで行う機械学習を指す言葉のようです。
Google I/O 2019のどこかのコマでは、より詳しい説明がされていると思うのですが、とりあえず基調講演で説明された内容だけでも簡単に言うと
- Googleアシスタントで利用されている音声モデルデータが改良されて小さくなっている
- 1セットあたり100GB ⇒ 0.5GB
んー。なるほど。よくわからん。
現在のスマホで実現されている音声アシスタントは、
インターネットを通じてサーバーとのやり取りが必要ですよね?

そうですね。
グーグルホームさんはオフラインだと
「Wi-Fiネットワークを確認して下さい」
とか言いますね。
なぜだかわかりますか?
なぜ?とは?
オンラインになっていないとダメな理由は実は明確です。
現在、返事の声データは音楽ファイルとしてサーバーからストリーミングしているからなんです。
音楽って、YouTube Music とかの?
そうです。仕組みとしては同じです。
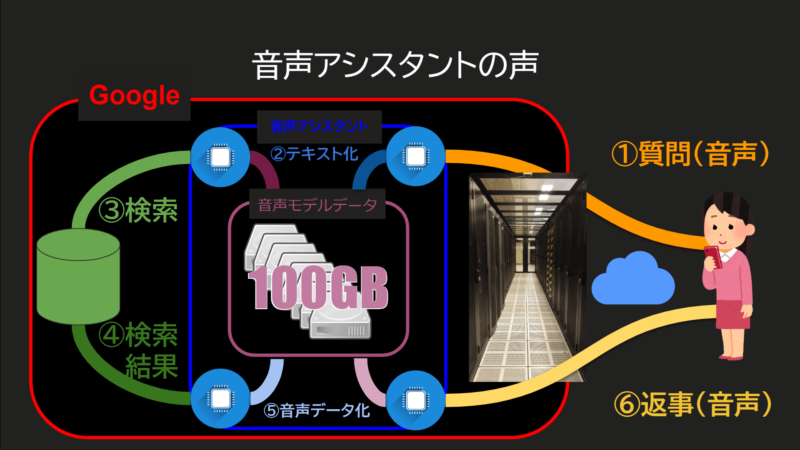
スマホやスマートスピーカーから、声による質問(コマンド)をサーバーに送った際、サーバーでは音声アシスタントが、音声モデルデータを参照しながらテキストに変換しています。
変換されたテキストから、その反応情報を検索。
検索結果の内容によって返事のテキストを生成、それを音声データに変換します。
変換された音声データはストリーミングという手段で、コマンドが送られた機器へ返送。
返送されたデータを再生します。
え、でもわりとウィキとかの内容喋ってますよ?
まさか世界中のウィキを音声に変換して用意してあるんですか?
いえ、リアルタイムで合成しているのです。
リアルタイム?!
なんでそんなお金掛りそうなことわざわざ?
音声モデルデータは当初100GBという大きなデータでした。
この大きな音声モデルデータを処理するにはサーバー側にデータを持つしかなかった訳です。
あー、なんかそれ小さくなったって自慢してた気がする。
そうです。なんと500メガまで小さくする事が出来たそうです。
これは、BERT(Bidirectional Encorder Representational from Transformers)による成果です。
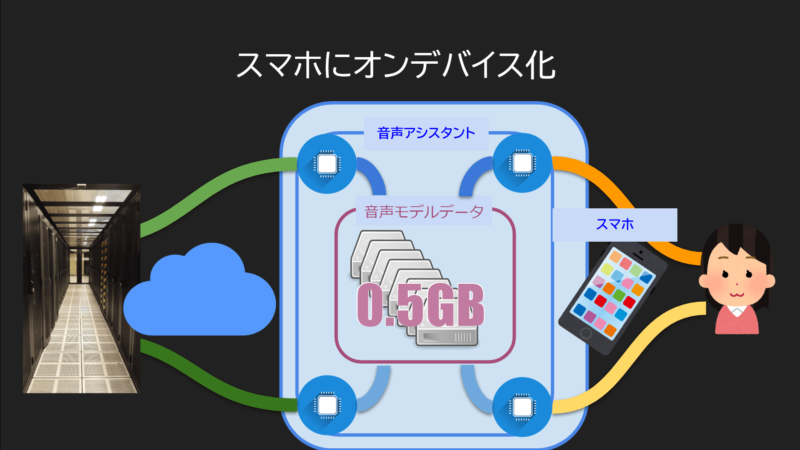
0.5GBまでサイズが小さくなったことでスマホの中に保存出来るようになったと同時に、データが小さいので処理速度も上がりました。
これにより、Googleの機械学習は次の段階へと進んだのです。
実際、Gboardの音声入力、えげつない速さですよね~。
あと音声文字変換アプリも速い。
っていうか世界征服どこいった。
つまり、グーグルは今後、とてつもない機械学習処理能力を得ると言うことです。
くわしく
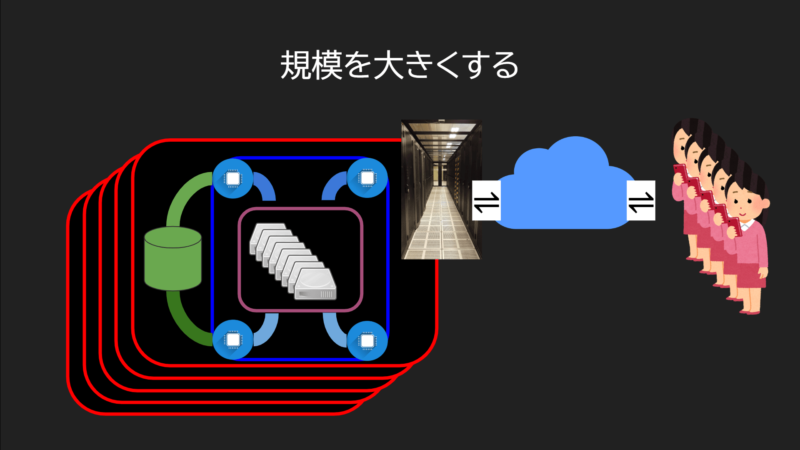
従来、ユーザーの数が増える毎に、処理すべきデータが増えると、サーバーをスケーリングしなければなりませんでした。
拡張するには1セットあたり100GBのデータを持つ装置を、データセンターに増やすことを意味します。
これは電気代を含めたホスト維持費が無限に増えていくと言うことです。
しかし、今後は、最小単位は0.5GBになり、スマホに実装されます。
これはサーバーの代わりにスマホがデータセンター役を担うことを意味しています。
そしてもちろん、サーバーの担当処理が減りますから、サーバーで維持すべき装置が減ります。
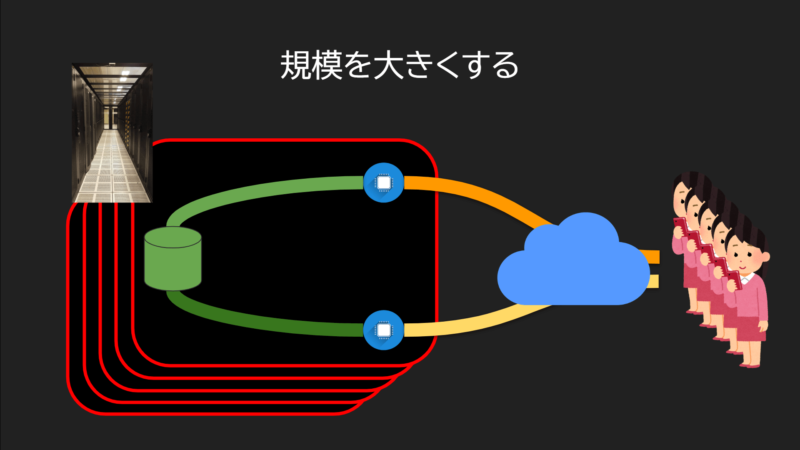
あ、なるほど。
正確には、待ち構える機能にスイッチしていくのでしょうけど、それでも、スマホに搭載していくわけですからね。
スマホに機械学習する子が搭載され、その学習データは定期的にサーバーにアップロード。
サーバーで統合された後、最新のデータセットになってスマホに帰ってきます。
これが連合学習、フェデレーションラーニングです。
良いことばかりのように聞こえますけど?
なにか問題が?
従来、Googleが機械学習の精度を上げるためには設備投資が必要でした。
サーバーやらなんやら。
でも今後は、お客さんが買っていくスマホが処理する様になりますよね?
端末が増えれば増えるほど、機械学習の精度は上がっていきますから、今後GoogleのAIはとんでもないレベルまで上がると思いますよ。
安いPixel 3aにも乗っていくわけですから、今までとは比べものにならない処理装置数になります。
正直、今後、数年、ひょっとすると数ヶ月単位でヤバいレベルの上がリ方をすると思いますね。
もうこれはAmazonの危機!支配構造かわっちゃう!
アレクサ危うし。ヤバいでござる、やばいでござるよ~~。
おちつけし
現在、スマートスピーカーと名前がついているものは、サーバーで処理した音声データを再生する道具でしかないことと、それが今後グーグルだけ違うステージに上がると言うこと。
たしかに、お高いAndroid端末に手が出なかった国々にも行き渡るようになれば、グーグルさんはお金を払ってデータの精度を上げてくれるお客さんをたくさん抱える事になるでしょう。
これは、ちょっとサラッと流せる話題じゃないよねw
ちょっと面白かった。